![[Java] Array, ArrayList, LinkedList 비교](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FmARCc%2FbtsrraCF67n%2FgONIb4kjHqvWVFq6VI7zz1%2Fimg.png)


Array (배열)
- 동일한 자료형(Data Type)의 데이터를 연속된 공간에 저장하기 위한 자료 구조
- 기본형(Primitive Types) 또는 인스턴스(Reference Type)을 저장하기 위해 배열 사용
- 처음 선언시 길이를 지정하기 때문에 런타임 환경에서 크기를 변경할 수 없다 (정적 할당, static allocation)
Array 선언 및 초기화 예시
# 1
int[] arr = new int[10];
arr[1] = 1; // .. 이하 생략
# 2
int[] arr = new int[] {1, 2, 3, 4};
# 3
int[][] arr = {{1, 0}, {0, 1}, {-1, 0}, {-1, 0}};
장점
구조가 간단하고, 인덱스로 해당 element에 접근할 경우 시간 복잡도 O(1) 소요 (=access time 짧다)
단점
크기 지정 후 변경할 수 없다 -> 크기 변경을 피하기 위해 충분히 큰 배열을 생성하면 메모리 낭비 발생
Arrays.class 에서 유용한 static method 제공한다
https://dev-ljw1126.tistory.com/316
[Java] Arrays 클래스 메서드 (자바의 정석)
개인적으로 코딩 테스트, 알고리즘 문제 풀이시 아래의 static method 필수로 알고 있는 것이 좋다고 생각한다 - Arrays.sort() - Arrays.fill() - Arrays.asList() - Arrays.stream() - Arrays.toString() - Arrays.copyOf() - Arrays
dev-ljw1126.tistory.com
ArrayList
- Java 1.2 추가 (Collection Framework 자료 구조)
- 저장 순서가 보장, 중복을 허용
- Object[] 에 자료를 담고 동적으로 가변 길이를 가진다
- 초기 배열 크기 : 10
- 크기를 초과할 경우 기존 크기 + 1 늘린 배열에 기존 elements를 copy 한 후 추가한다 (참고1)
//java.util.ArrayList 제네릭 클래스
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData;
- Object[] elementData에 요소를 저장한다
- 자바의 모든 클래스는 Object를 상속하기 때문에 배열에 담을 수 있다
장점
- 내부적으로 Object[] 배열을 이용하여 요소 저장하므로, 인덱스를 이용해 element 에 빠른 접근이 가능하다
- 리스트의 길이가 가변적이다 (동적할당, dynamic allocation)
단점
- element 추가시 배열 크기를 초과할 경우, 사이즈 증가시켜 copy하는 방식으로 요소를 추가하여 지연이 발생하게 된다
- 비순차적(임의 중간) 위치에 추가/삭제가 일어날 경우 Copy/Shift 비용 발생하여 최악의 경우 시간 복잡도 O(N) 만큼 소요
(단, 순차적(마지막 위치)으로 element 삽입/삭제가 일어날 경우 shift 비용 발생하지 않아 빠르다)
참고1. add() 에서 기존 배열 크기 보다 클 경우
기존 크기만큼 배열이 다 차있는 경우 1씩 크기를 증가시켜 신규 요소를 추가
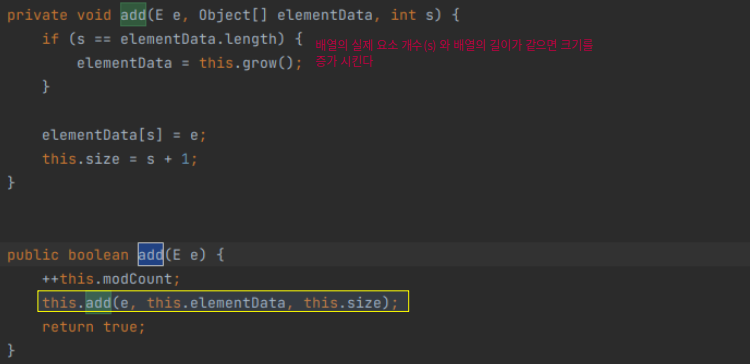
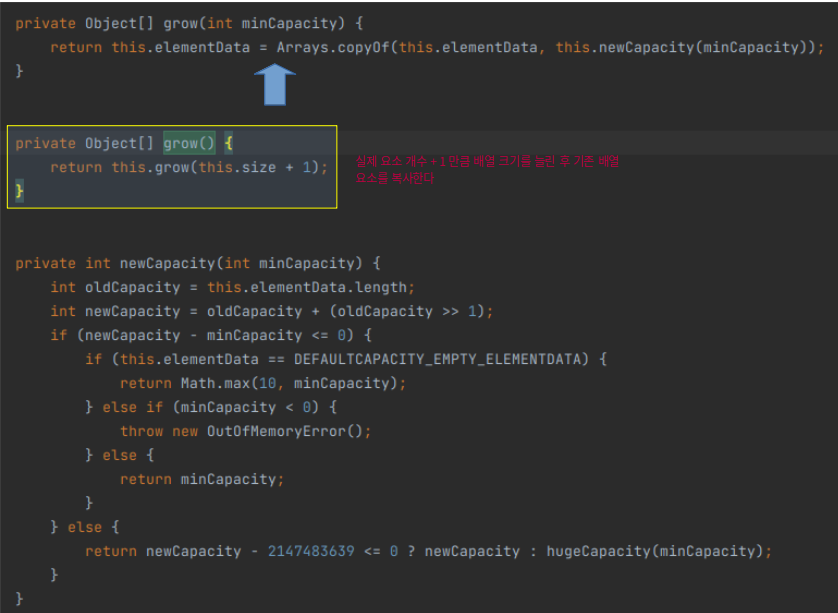

add()에서 사이즈 초과시 배열 크기를 1씩 증가한다는 것을 처음 알았다
참고2. addAll() 에서 추가 배열이 기존 배열 크기를 초과할 경우
ArrayList.class에 addAll() 메서드를 살펴봤을 때, 추가 배열의 크기가 기존 배열보다 클 경우 배열 크기를 증가시켜 기존 요소를 복사하게 된다 (기존 배열 요소의 개수 + 신규 배열의 크기)
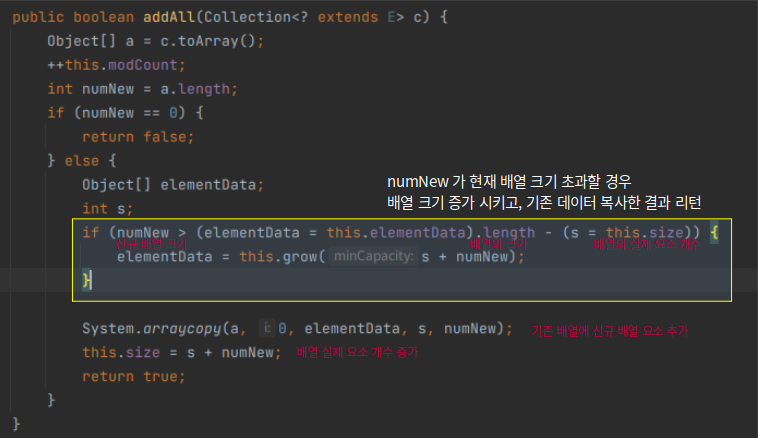
배열의 최대 크기는 약 21억으로 지정되어 있고, 최대 크기를 넘지 않는 경우 minCapactiry로 기존 배열이 복사된다
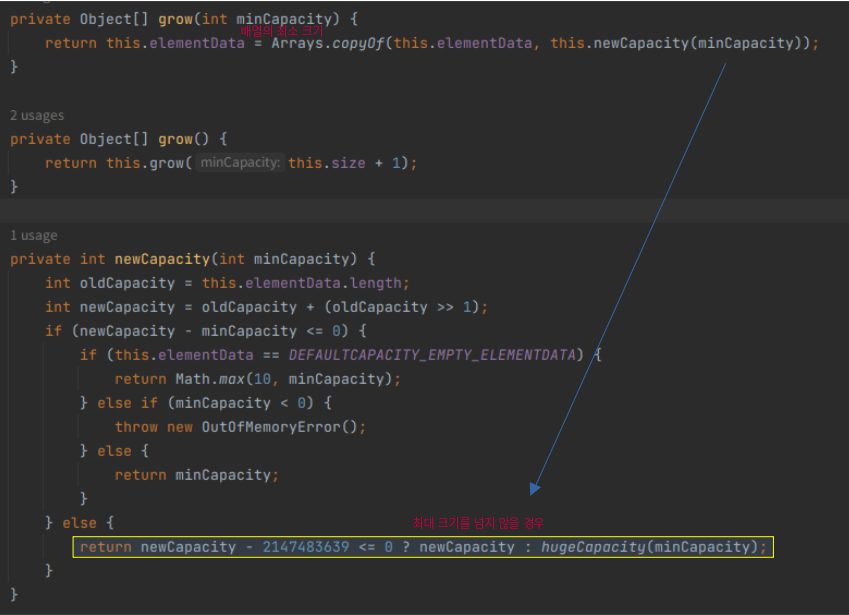
예시. Arrays.copyOf(T[] original, int newLength)
int[] nums = new int[]{1, 2, 3, 4, 5};
int[] copyOfNum = Arrays.copyOf(nums, 10);
System.out.println(Arrays.toString(copyOfNum)); // [1, 2, 3, 4, 5, 0, 0, 0, 0, 0]
Arrays.copyOf()는 내부적으로 System.arraycopy()를 호출하고 있었다
public static int[] copyOf(int[] original, int newLength) {
int[] copy = new int[newLength];
System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength));
return copy;
}
예시. System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
src : source 배열
srcPos : source 배열에서 복사 시작 위치
dest : traget 배열 (= 기존 배열/크기가 늘어난 기존 배열)
destPos : target 배열에서 복사 시작 위치
length : source 배열에서 복사할 요소의 개수
@Test
void SystemArrayCopy() {
//given
int[] source = new int[] {6, 7, 8, 9, 10};
int[] dest = new int[] {1, 2, 3, 4, 5, 0, 0 ,0 ,0 ,0};
//when
System.arraycopy(source, 0, dest, 5, 5); // source 의 0번 인덱스 부터 5개 요소를 dest 배열에 5번 인덱스부터 넣는다
//then
assertThat(dest).containsExactly(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); // Ok
}
참고3. fastremove() , 요소 삭제할 경우
- remove(Object o) 호출할 경우 삭제할 요소의 인덱스를 찾은 후 아래 fastRemove()를 호출한다
- 삭제하는 요소의 위치 i 에 대해 i + 1부터 newSize - 1 개수만큼 shift가 이루어진다 (=복사가 이뤄진다)
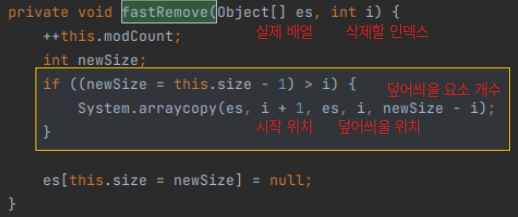
예시. 5를 삭제할 경우
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[1, 2, 3, 4, 6, 7, 8, 9, 10, null]
LinkedList
- Java 1.2 추가 (Collection Farmework 자료 구조)
- 불연속으로 존재하는 노드(객체)를 주소 포인터로 링크(참조)함으로써 이어지는 구조
- 고정 크기로 인해 크기 변경을 못하는 Array(배열)의 단점을 보완
- 단방향 연결 리스트(Singly LinkedList), 양방향 연결 리스트(Doubly LinkedList), 양방향 원형 연결 리스트(CircularDoublyLinkedList)
java.util 패키지의 LinkedList<T> 의 경우 Doubly LinkedList 인 것을 확인 가능하다

장점
- 노드를 포인터로 연결하는 방식 사용하여 배열 크기에 대한 제약이 없어짐
- 비순차적(임의 위치) 데이터 삽입/삭제 시 노드 생성 후 포인터만 수정하면 되므로, 자료의 삽입과 삭제가 용이
단점
- 검색시, 추가/삭제 시 노드를 순차 접근하여 찾으므로 데이터 접근성이 나쁘다 (= 탐색 시간 많이 소요)
- 링크 연결/해지 과정과 next, prev 노드에 대한 비용 발생
직접 구현 해 본 Doubly LinkedList
java.util.LinkedList 참고하여 추가/삭제 구현을 해보았다
1) 클래스 선언
- first 노드의 경우 prev가 null 이다
- last 노드의 경우 next가 null 이다
public class MyLinkedList<E> {
int size; // 연결 요소의 개수
Node<E> first; // 시작 노드
Node<E> last; // 마지막 노드
private static class Node<E> {
E item;
Node<E> next; // 이전 노드 주소
Node<E> prev; // 다음 노드 주소
public Node(Node<E> prev, E element, Node<E> next) { // 가독성 good
this.item = element;
this.next = next;
this.prev = prev;
}
}
//..
}
2) 추가
순차적으로 노드를 추가할 경우
- add(E e) 호출시 내부적으로 linkLast(E e) 호출
처음 위치에 노드 추가할 경우
- addFirst(E e) 호출 시 내부적으로 linkFirst(E e) 호출
마지막 위치에 노드 추가할 경우
- addLast(E e) 호출 시 내부적으로 linkLast(E e) 호출
비순차적(임의) 위치에 노드 추가할 경우
- linkBefore(E e, Node<E> target) 호출하여 target 노드 앞에 신규 노드를 추가
그리고 신규 노드 추가시 공통적으로 포인터 연결(링크) 작업을 수행한다
public void addFirst(E e) {
this.linkFirst(e);
}
public void addLast(E e) {
this.linkLast(e);
}
public boolean add(E e) {
this.linkLast(e);
return true;
}
private void linkFirst(E e) {
Node<E> f = this.first;
Node<E> newNode = new Node<>((Node) null, e, f); // first 노드는 prev = null
this.first = newNode; // *누락 실수
if(f == null) { // 노드가 하나 뿐인 경우
this.last = newNode;
} else {
f.prev = newNode;
}
this.size += 1;
}
private void linkLast(E e) {
Node<E> l = this.last;
Node<E> newNode = new Node(l, e, (Node<E>)null); // last 노드는 next = null
this.last = newNode;
if(l == null) { // 노드가 하나 뿐인 경우
this.first = newNode;
} else {
l.next = newNode;
}
this.size += 1;
}
void linkBefore(E e, Node<E> target) { // target 노드 앞에 삽입
Node<E> prev = target.prev;
Node<E> newNode = new Node(prev, e, target);
if(prev == null) { // 이전노드가 prev == null이면 헤드
this.first = newNode;
} else {
prev.next = newNode;
}
this.size += 1;
}
3) 삭제
마찬가지로
- remove() 호출할 경우 unlink() 호출하여 링크 해지/연결 처리
- removeFirst() 호출할 경우 unlinkFirst() 호출하여 링크 해지/연결 처리
- removeLast() 호출할 겨웅 unlinkLast() 호출하여 링크 해지/연결 처리
private E unlinkFirst(Node<E> f) {
E element = f.item;
Node<E> next = f.next;
this.first = next;
if(next == null) { // 노드가 한 개 뿐이면
this.last = null;
} else {
next.prev = null; // 시작 노드는 prev = null 이다
}
f.item = null;
f.next = null;
this.size -= 1;
return element;
}
private E unlinkLast(Node<E> l) {
E element = l.item;
Node<E> prev = l.prev;
this.last = prev;
if(prev == null) { // 노드가 한개 뿐이면
this.first = null;
} else {
prev.next = null; // 마지막 노드는 next = null 이다
}
l.item = null;
l.prev = null;
this.size -= 1;
return element;
}
private E unlink(Node<E> x) {
E element = x.item;
Node<E> prev = x.prev;
Node<E> next = x.next;
if(prev == null) { // prev = null 은 x가 시작노드라는 것을 뜻함
this.first = next;
} else {
prev.next = next;
x.prev = null;
}
if(next == null) { // next = null은 x가 마지막 노드라는 것을 뜻함
this.last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
this.size -= 1;
return element;
}
public boolean remove(Object o) {
Node x;
if(o == null) {
for(x = this.first; x != null; x = x.next) {
if(x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.first; x != null; x = x.next) {
if(o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}
public void removeFirst() {
Node<E> f = this.first;
if(f == null) {
throw new NoSuchElementException();
} else {
this.unlinkFirst(f);
}
}
public void removeLast() {
Node<E> l = this.last;
if(l == null) {
throw new NoSuchElementException();
} else {
this.unlinkLast(l);
}
}
개인적으로 method를 용도별로 분리하다보니 읽기 편하고, 링크 해지시 null 처리하는게 깔끔해 보였다
ArrayList vs LinkedList
요약
- 추가/삭제의 경우 LinkedList 성능 이점 가짐
- 탐색의 경우 ArrayList 성능 이점 가짐
탐색의 경우
- ArrayList는 내부적으로 Object[] 로 자료 관리하기 때문에 인덱스로 접근할 경우 O(1) 소요
- LinkedList의 경우 포인터를 순차 조회하여 찾으므로 O(N) 소요
추가/삭제의 경우
| LinkedList | ArrayList | |
| 첫번째 위치 | O(1) | O(1) 또는 O(N) |
| 마지막 위치 | O(1) | O(1) 또는 O(N) |
| 임의 위치 (비순차적) | O(1) + 탐색 시간 | O(N) |
만약 배열에 값이 없다면 ArrayList 는 상수 시간 안에 추가/삭제가 가능하나, 배열에 값이 다 차있거나, 임의 위치 대상으로 추가/삭제 수행할 경우 copy(shift) 비용 발생하여 최악의 경우 O(N) 만큼 소요된다
반면 LinkedList의 경우 링크 연결/해지하면 되기 때문에 탐색 시간까지 포함하더라도 ArrayList 보다 추가/삭제시 성능에서 이점을 가진다
참고
자바의 정석 - LinkedList 와 ArrayList 비교
ArrayList vs LinkedList 특징 & 성능 비교-인파 기술 블로그
'알고리즘 > 자료구조' 카테고리의 다른 글
| [BOJ22252] 정보 상인 호석 (자료구조, 해쉬맵, 우선 순위 큐) (0) | 2023.09.16 |
|---|---|
| [BOJ21276] 계보 복원가 호석 (자료구조, 해시맵, 인접 리스트, 그래프) (0) | 2023.09.13 |
| [BOJ10799] 쇠막대기 (스택, 자료구조) (0) | 2023.09.13 |
| [Java] HashMap Method, 해싱 충돌 살펴보기 (0) | 2023.08.19 |
| [Java] Set , HashSet 살펴보기 (0) | 2023.08.19 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[BOJ21276] 계보 복원가 호석 (자료구조, 해시맵, 인접 리스트, 그래프)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fc1n14G%2Fbtst0alcw2o%2FHKwKNhddlnR297OAo9vvcK%2Fimg.png)
![[BOJ10799] 쇠막대기 (스택, 자료구조)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FObSsl%2FbtstWMliVZz%2FafzLvwgHTeksakLZ0Kuqx1%2Fimg.png)
![[Java] HashMap Method, 해싱 충돌 살펴보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbhTNwI%2FbtsrErQJvXG%2FpkpAtutXqwI5WWOKbmMG61%2Fimg.png)
![[Java] Set , HashSet 살펴보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcgeAwV%2FbtsrIbNphDP%2F18TFJBGtwdOzDQh5YFVUY0%2Fimg.png)