


온라인 코드 테스트 사이트
https://www.jdoodle.com/execute-nodejs-online/
빅오 표기법(Big-O Notation)

| 시간 복잡도 | 의미 |
| O(1) | 상수 시간(constant time) |
| O(logN) | 로그 시간(log time) |
| O(N) | 선형 시간(linear time) |
| O(NlogN) | 로그 선형 시간(log-linear time) |
| O(N^2) | 이차 시간(quadratic time) |
| O(N^3) | 삼차 시간(cubic time) |
| O(2^N) | 지수 시간(exponential time) |
- 시간 복잡도 (time complexity) : 알고리즘에 사용되는 연산 횟수 측정
- 공간 복잡도 (space complexity) : 알고리즘에 사용되는 메모리의 양을 측정
공간을 많이 사용하는 대신 시간을 단축하는 방법이 흔히 사용됨
Ch01. 기본 문법
입출력 방법과, JavaScript 기본 문법, 그리고 API 에 대해서도 살펴보도록 하였다.
입출력
1. fs 모듈 방식
// fs 모듈 이용해 입력 전체를 읽어 처리하는 방식
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');2. readline 모듈 방식
// 한 줄씩 입력 받아 처리할 경우 readline 모듈을 사용할 수 있다.
const rl = require('readline').createInterface({
input : process.stdin,
output : process.stdout
});
let rlInput = [];
rl.on('line', function(line) {
// 콘솔 창에서 입력 후 줄바꿈(Enter)을 입력할 때마다 호출
rlInput.push(line);
}).on('close', function() {
//콘솔 입력 창에서 ctrl + c 혹은 ctrl +d 를 입력하면 호출(입력 종료됨!)
console.log(rlInput);
process.exit();
});Tip. 코딩 테스트에서 출력 결과를 매번 console.log() 실행하지 않고, 하나의 문자열로 결과를 저장한 후 처리하게 되면 출력 시간 단축 가능 !
조건문
#1
if(조건1) {
// do something
} else if(조건2) {
// do something
} else {
// do something
}
#2
if(조건1) // do something
else if(조건2) // do something
else // do something
#3
if(조건1)
// do something
else if(조건2)
// do something
else
// do something개인적으로 #1 방식으로 if 조건문 작성하는 것을 선호
반복문 (for, while)
#1
for(초기문; 조건문; 증감문) {
// do something;
}
#2
for(초기문; 조건문; 증감문) // do something
#3 들여쓰기
for(초기문; 조건문; 증감문)
// do somethingfor문의 경우 #1 방식 선호함 ({} 블록 안에 작성하여 예상치 못한 오류 방지 가능)
/*조건문이 참인 경우에만 블록 내부 코드 실행*/
while(조건문) {
// do something
}배열
문제1) 최소, 최대 (링크)
문제2) 최댓값 (링크)
Math.max() 매개변수에 spread 로 할당 가능한 걸 알게 됨
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
let data = input.map(x => Number(x));
let max = Math.max(...data);
console.log(max);
console.log(data.indexOf(max) + 1);
문제3) 나머지 (링크)
Set 을 사용하면 간단
문제4) 평균은 넘겠지 (링크)
문제5) 평균 (링크)
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = Number(input[0]);
const score = input[1].split(' ').map(Number);
const maxScore = Math.max(...score);
const fixedScore = score.map(s => s/maxScore * 100);
const fixedTotalScore = fixedScore.reduce((acc, cur) => acc + cur);
console.log(`${fixedTotalScore/n}`);문자열
문제2) 문자열 반복 (링크)
// #내 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const testCase = Number(input[0]);
let result = "";
for(let i = 1; i <= testCase; i++) {
const data = input[i].split(' ');
const repeatCnt = Number(data[0]);
for(let t of data[1]) {
result += t.repeat(repeatCnt);
}
result += "\n";
}
console.log(result);
// #강의 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const testCase = Number(input[0]);
for(let i = 1; i <= testCase; i++) {
let [r, s]= input[i].split(' ');
let result = "";
// String.prototype.charAt(idx)
for(let j = 0; j <= s.length; j++) {
result += s.charAt(j).repeat(r);
}
console.log(result);
}
문제3) 상수 (링크)
// #내 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
function reverseString(str) {
const splitString = str.split('');
const reverseStr = splitString.reverse();
return reverseStr.join('');
}
const data = input[0].split(' ');
const num1 = Number(reverseString(data[0]));
const num2 = Number(reverseString(data[1]));
console.log(Math.max(num1, num2));
// #강의 답안 (더 간단한 듯)
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
let a = input[0].split(' ')[0];
let b = input[0].split(' ')[1];
let newA = a[2] + a[1] + a[0];
let newB = b[2] + b[1] + b[0];
console.log(Math.max(Number(newA), Number(newB)));
문제4) 그룹 단어 체커 (링크)
// 내 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
function isGroupWord(word) {
const mySet = new Set(word[0]);
for(let i = 1; i < word.length; i++){
if(word[i] !== word[i-1]) {
if(mySet.has(word[i])) {
return false;
} else {
mySet.add(word[i]);
}
}
}
return true;
}
const n = Number(input[0]);
let result = 0;
for(let i = 1; i <= n; i++) {
const word = input[i];
if(isGroupWord(word)) result++;
}
console.log(result);
// 강의 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
function check(data) {
let alphabetSet = new Set(data[0]); //*
for(let n = 0; n < data.length -1; n++) {
if(data[n] !== data[n+1]) {
if(alphabetSet.has(data[n + 1])) {
return false;
} else {
alphabetSet.add(data[n + 1]);
}
}
}
return true;
}
const n = Number(input[0]);
let result = 0;
for(let i = 1; i <= n; i++) {
let data = input[i];
if(check(data)) result += 1;
}
console.log(result);
문제5) 단어의 개수 (링크)
단어가 없는 경우에 대해 확인 못해서 시간 소모
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
let words = input[0].trim().split(" ");
if(words == "") console.log(0);
else console.log(words.length);Ch02. 자료구조
다수의 자료(data)를 담기 위한 구조, 형태
배열(Array)와 리스트(List)
배열과 리스트를 비교시, 배열과 LinkedList 에 대해 설명하는게 일반적으로 알고 있음
배열 (Array)
- 기본적인 자료 구조로써 여러 개의 변수를 담는 공간
- 컴퓨터의 메인 메모리에서 배경 공간은 연속적으로 할당됨 (=논리적, 물리적으로 연속적으로 저장됨)
- 배열은 인덱스(index)가 존재하며, 인덱스로 접근 가능 => O(1)
- 장점 : 캐시 히트(cache hit) 가능성이 높으며, 조회가 빠르다.
- 단점 : 일반적으로 배열의 크기를 미리 지정해야 하므로, 데이터 추가 및 삭제에 한계가 있다. => O(N)
- 자바스크립트에서는 동적 배열의 특징을 가지고 있음
연결 리스트 (Linked List)
- 배열과 달리 크기가 정해져 있지 않고, 리스트의 크기는 동적으로 변경 가능함
- 장점 : 포인터(pointer)를 통해 다음 데이터 위치를 가리킨다는 점에서 삽입과 삭제가 간단하고, 배열처럼 미리 공간 할당할 필요 없음
- 단점 : 특정 원소 검색 시 순차적으로 수행해야 하므로, 데이터 검색 속도가 느리다 => O(N)
*참고
- (자바) Array , ArrayList , LinkedList
- (자바) ArrayList 와 LinkedList 차이
*JavaScript의 배열
- JavaScript의 배열 자료형은 동적 배열이다.
- 배열의 용량이 가득 차면, 자동으로 크기를 증가 시킴
- 내부적으로 포인터(pointer)를 사용하여, 연결 리스트의 장점도 가짐
- 단, 큐(queue)의 기능을 제공하지 못한다. (비효율적)
*배열 초기화
// #1 대괄호 사용하기
let arr = [];
arr.push(7);
arr.push(8);
console.log(arr); // [7, 8]
// #2 Array() 사용하기
let arr = new Array();
// #3 직접 할당
let arr = ["a", "b", "c"];
// #4
let arr = new Array(5).fill(0); // [0, 0, 0, 0, 0]
// #5
let arr = Array.from({length : 5}, () => 7); // [7, 7, 7, 7, 7]
// #6 2차원 리스트(배열)
let arr = Array.from(Array(4), () => new Array(5)); // 4행 5열 2차원 배열 생성
// #7 반복문을 이용해 2차원 배열 초기화
let arr = new Array(3);
for(let i = 0; i < arr.length; i++) {
arr[i] = Array.from({length : 4}, (_, j) => i * 4 + j); // j : 0 ~ 3 (인덱스)
}
// 실행 결과
[
[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]
]
*배열의 대표적인 메서드
- concat() : 여러 개의 배열을 이어 붙여서 합친 결과 반환 => O(N)
- slice(from, to) : from ~ (to - 1) 까지 원소를 꺼낸 배열을 반환 => O(N)
- indexOf() : 특정한 값을 가지는 원소의 첫째 인덱스 반환 (없는 경우 -1 반환) => O(N)
그외 reduce(), map() 등 prototype으로 제공되는 다양한 메서드에 대해서도 살펴보자 (아래 링크 참고)
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/reduce
Array.prototype.reduce() - JavaScript | MDN
reduce() 메서드는 배열의 각 요소에 대해 주어진 리듀서 (reducer) 함수를 실행하고, 하나의 결과값을 반환합니다.
developer.mozilla.org
https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Global_Objects/Array/map
Array.prototype.map() - JavaScript | MDN
map() 메서드는 배열 내의 모든 요소 각각에 대하여 주어진 함수를 호출한 결과를 모아 새로운 배열을 반환합니다.
developer.mozilla.org
스택(Stack)
- 데이터를 임시 저장할 때 사용하는 자료구조
- 기본적인 배열(Array) 자료형으로 스택 구현 가능
- LIFO(Last In First Out, 후입선출), FILO(First In Last Out, 선입후출) 방식

let stack = [];
stack.push(5);
stack.push(2);
stack.push(3);
stack.push(7);
stack.pop();
stack.push(1);
stack.push(4);
stack.pop();
let reversed = stack.slice().reverse(); // slice()로 배열 새로 리턴 받아서 리버스
console.log(reversed); // 최상단 원소 부터 출력, [1, 3, 2, 5]
console.log(stack); // 최하단 원소부터 출력, [5, 2, 3, 1]
| 연산 | 시간 복잡도 | 설명 |
| 삽입(Push) | O(1) | 스택에 원소 삽입 (마지막 위치) |
| 추출(Pop) | O(1) | 스택에 원소 추출 (마지막 위치) |
| 최상위 원소 확인(Peek) | O(1) | - |
| Empty | O(1) | 스택이 비어있는지 확인 |
큐(Queue)
- 스택(Stack)과 마찬가지로 데이터를 임시 저장하기 위한 자료구조
- 먼저 삽입된 데이터가 먼저 추출되는 방식 ( FIFO : First In First Out, 선입선출 )
- 연결 리스트로 큐를 구현시 머리(head)와 꼬리(tail) 두 개의 포인터를 가짐
- 자바 스크립트에서는 "Dictionary 자료형"을 이용하여 큐를 구현하면 간단
- 삽입과 삭제에 있어서 시간복잡도 O(1) 보장
Dictionary는 자바스크립트에는 없는 자료형으로 Object(객체)와 동일

트리(Tree)
- 계층 구조를 표현할 때 사용할 수 있는 자료구조
- 트리(Tree)에서는 부모와 자식 관계가 성림함 (<-> 그래프의 경우 부모와 자식 관계 없음)

| 용어 | 설명 |
| Root Node | 부모가 없는 최상위 노드 |
| Leaf Node(단말 노드) | 자식이 없는 노드 |
| Depth(깊이) | 루트 노드에서의 길이 (length) |
| Height(높이) | 루트 노드에서 가장 깊은 노드까지의 길이를 의미 |
| Sibling(형제 노드) | 동일한 부모 노드를 가지는 형제 노드 |
이진 트리(Binary Tree)
- 최대 2개의 자식 노드를 가진 수 있는 트리
이진 탐색 트리(Binary Search Tree)
- 부모 노드 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 노드로 구성된 트리
- 데이터 검색(탐색)에 주로 사용
- 평균 시간 복잡도 O(logN) 보장
- 최악의 경우 O(N)으로 LinkedList와 동일한 성능

우선 순위 큐(Priority Queue)
- 우선 순위에 따라 데이터를 추출하는 자료구조
- 일반적으로 힙(heap)을 이용해 구현
- 이진 트리(binary tree) 구조를 이용해서 구현 (비선형 자료구조)
| 우선순위 큐 구현 방식 | 삽입 시간 | 삭제 시간 |
| 리스트 자료형 | O(1) | O(N) |
| 힙(Heap) | O(logN) | O(logN) |
- 종류
1. 포화 이진 트리 : 리프 노드를 제외한 모든 노드가 두 자식을 가지고 있는 트리
2. 완전 이진 트리 : 모든 노드가 왼쪽 자식 부터 차근차근 채워진 트리
3. 높이 균형 트리 : 왼쪽 자식 트리와 오른쪽 자식 트리의 높이가 1이상 차이 나지 않는 트리
힙(heap)
- 원소 중에서 최대값 또는 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리 형태의 자료 구조
- 최대 힙(max heap) : 값이 큰 원소부터 추출함
- 최소 힙(min heap) : 값이 작은 원소부터 추출함
- 원소 삽입/삭제를 위해 O(log N)의 수행 시간 걸림 => 단순 N개의 데이터 삽입, 삭제할 경우 O(NlogN)의 시간복잡도 가짐

| 최소 힙 | 최대 힙 |
| - 부모 노드의 키 값이 자식 노드의 키 값보다 항상 작다 - 루트 노드가 가장 작다 - 값이 작은 데이터가 우선 순위를 가진다 |
- 부모 노드의 키 값이 자식 노드의 키 값보다 항상 크다 - 루트 노드가 가장 크다 - 값이 큰 데이터가 우선 순위를 가진다 |
*heapify
- 원소 삽입, 삭제시 최대 또는 최소 힙의 성질을 만족하도록 이진 트리 정렬 하는 과정
*힙에 새로운 원소가 삽입되는 경우 (최대힙의 경우)
- 마지막 노드에 원소를 삽입
- 부모 노드와 현재 노드를 비교하여, 부모 보다 큰 경우 현재 노드와 위치를 교체함 (Root Node, 최상위 노드까지 진행)
- 시간 복잡도 : O(log N)
*힙에서 원소가 제거 되는 경우 (최대 힙의 경우)
- Root Node 제거
- 그리고 이진 트리의 마지막 노드를 Root Node로 이동 시킨 후 아래 쪽으로 내려가면서 heapify
- 시간 복잡도 : O(log N)
heapify 시 비교할 노드의 개수가 절반씩 되므로 삽입과 삭제에 대한 시간 복잡도는 O(log N)이다
*우선 순위 큐 라이브러리 https://github.com/ndb796/priorityqueuejs
// index.js 사용
// 최대힙(max heap)
let pq = new PriorityQueue(function(a,b) {
return a.cash - b.cash;
});
pq.enq({cash : 250, name : 'Doohyun kim'});
pq.enq({cash : 300, name : 'Gildong hong'});
pq.enq({cash : 150, name : 'Minchul Han'});
console.log(pq.size()); // 3
console.log(pq.deq()); // {cash : 300, name : 'Gildong hong'}
console.log(pq.peek()); // {cash : 250, name : 'Doohyun kim'}
console.log(pq.size()); // 2
그래프(Graph)
- 사물을 정점(vertex)과 간선(edge)으로 나타내기 위한 도구
- 그래프는 두 가지 방식으로 구현할 수 있다.
1. 인접 행렬(adjacency matrix) : 2차원 배열 사용 하는 방식
2. 인접 리스트(adjacency list) : 연결 리스트를 이용하는 방식
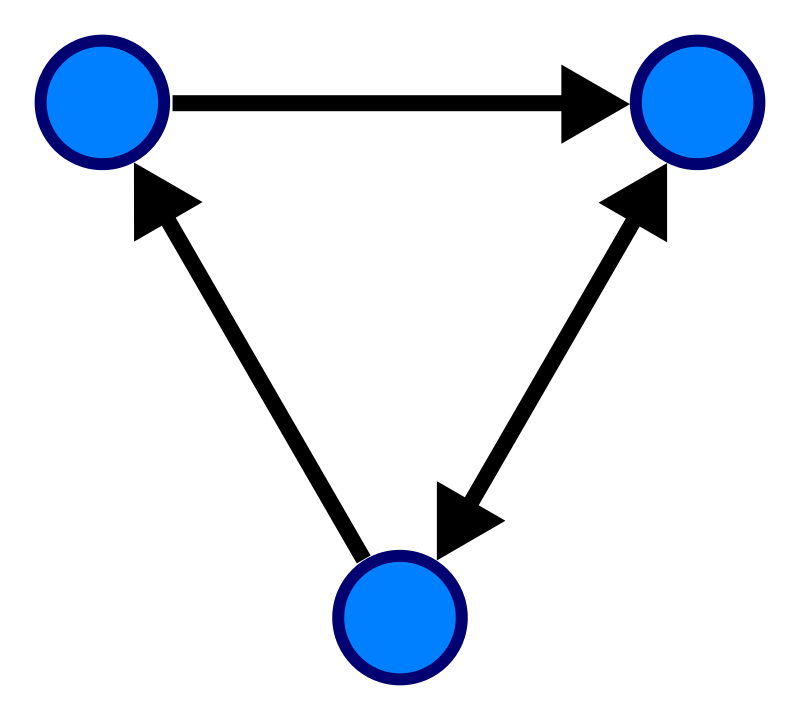
*인접 행렬 - 무방향 무가중치 그래프
- 무방향 = 양방향
let graph = [
[0, 1, 1, 0], // 0번 노드(row)는 1번, 2번 노드(col)와 연결되어 있다
[1, 0, 1, 0],
[1, 1, 0, 1],
[0, 0, 1, 0]
]
*인접 행렬 - 방향 가중치 그래프
let graph = [
[0, 0, 7, 0], // 0번 노드 -> 2번 노드 연결되어 있고 가중치는 7
[3, 0, 8, 0],
[0, 8, 0, 0], // 2번 노드 -> 1번 노드 연결되어 있고 가중치는 8
[0, 0, 4, 0] // 3번 노드 -> 2번 노드 연결되어 있고 가중치는 4
]
*인접 리스트 - 무방향 무가중치 그래프
- 무방향 = 양방향
let graph = [
[1, 2], // 0번 노드에 1,2 번 노드가 연결되어 있다 (무방향)
[0, 2], // 1번 노드에 0,2 번 노드가 연결되어 있다
[0, 1, 3], // 2번 노드에 0,1,3 번 노드가 연결되어 있다
[2] // 3번 노드에 2 번 노드가 연결되어 있다
]
*인접 리스트 - 방향 가중치 그래프
let graph = [
[(2, 7)], // 0번 -> 2번 노드로 갈 때 비용이 7
[(0, 3), (2, 8)],
[(1, 8)], // 2번 -> 1번 노드로 갈 때 비용이 8
[(2, 4)] // 3번 -> 2번 노드로 갈 때 비용이 4
];
| 장점 | 단점 | |
| 인접 행렬 | 두 노드의 연결 여부를 O(1)에 확인 가능 | 2차원 배열로 모든 정점의 연결 여부를 저장해야 하므로, 공간 효율성 떨어짐 O(V^2) |
| 인접 리스트 | 연결된 간선 정보만을 저장하여 공간 효율이 좋다 O(V + E) |
두 노드의 연결 여부를 확인 하기 위해 O(V)만큼의 시간 필요 |
최단 경로 알고리즘을 구현할 때, 인접 리스트*가 유리 !
Ch03. 정렬 알고리즘
선택(selection) 정렬
- 시간 복잡도 : O(N^2)
버블(bubble) 정렬
- 시간 복잡도 : O(N^2)
삽입(insertion) 정렬
- 시간 복잡도 : O(N^2)
- 선택, 버블 정렬보다 연산이 좀 더 적으므로 상대적으로 나음
병합(merge) 정렬
- 시간 복잡도 : O(NlogN)
- 동작 방식 ( 재귀 호출* 활용 )
1. 분할(divide) : 큰 문제를 작은 부분 문제로 분할
2. 정복(conquer) : 작은 부분 문제를 각각 해결
3. 조합(combine) : 해결한 부분 문제의 답을 이용하여 다시 큰 문제를 해결
- 장점 : O(NlogN) 의 시간 복잡도를 보장
- 단점 : 재귀 함수 호출로 인해 오버 헤드 발생 가능하고, 마찬가지로 임시 배열 저장 공간 필요함
Array.prototype.sort()는 어떤 정렬을 사용하는 걸까?
https://d2.naver.com/helloworld/0315536
문제2-1) 좌표 정렬하기 (링크)
또 어렵게 생각하는 안 좋은 습관이 나타났던 문제
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = Number(input[0]);
const data = [];
for(let i = 1; i <= n; i++) {
const [x, y] = input[i].split(' ').map(Number);
data.push([x, y]);
}
data.sort((a , b) => {
if(a[0] != b[0]) return a[0] - b[0]; // x좌표 기준 오름차순
else return a[1] - b[1]; // y좌표 기준 오름차순
})
let result = "";
for(let point of data) {
result += `${point[0]} ${point[1]}\n`;
}
console.log(result);
문제2-2) 좌표 정렬하기 2 (링크)
문제2-1과 내용은 동일하며, 내림차순 정렬 문제 (생략)
문제2-3) 단어 정렬 (링크)
자바스크립트에서 텍스트 정렬에 대해 이해도가 낮았음 (다시 풀어보기)
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = Number(input[0]);
let data = [];
for(let i = 1; i <= n; i++) {
data.push(input[i]);
}
data = [...new Set(data)];
data.sort((a , b) => {
if(a.length != b.length) { // 길이가 같지 않다면 짧은 순
return a.length - b.length;
} else { // 길이가 같으면 사전 순으로 정렬
if(a < b) return -1;
else if(a > b) return 1;
else return 0;
}
});
let result = "";
for(let x of data) {
result += `${x}\n`;
}
console.log(result);
문제3-1) 좌표 압축 (링크)
Set을 사용해서 중복 제거 후 정렬까지 아이디어는 맞았으나, indexOf()로 순서 맵핑 하면서 시간초과 발생
=> Map의 경우 get() 할 때 O(1)만큼의 시간 소요됨
// 강의 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = Number(input[0]);
const arr = input[1].split(' ').map(Number);
let uniqueArray = [...new Set(arr)];
uniqueArray.sort((a, b) => a - b);
let myMap = new Map();
for(let i = 0; i < uniqueArray.length; i++) {
myMap.uniqueArray(arr[i], i);
}
let result = "";
for(x of arr) {
result += myMap.get(x) + " "; // O(1) 소요
}
console.log(result);
문제3-2) 나이순 정렬 (링크)
Node.js의 정렬은 기본적으로 stable제공하므로, 나이 순 정렬만 처리하면 되었음
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = Number(input[0]);
const data = [];
for(let i = 1; i <= n; i++) {
const info = input[i].split(' ');
data.push([Number(info[0]), info[1]]);
}
data.sort((a , b) => a[0] - b[0]);
let result = "";
for(let j = 0; j < data.length; j++) {
result += `${data[j][0]} ${data[j][1]}\n`;
}
console.log(result);
문제3-3) 소트인사이드 (링크)
10억개라서 sort() 로 풀어도 통과되었으나, 강의 답안에 계수 정렬 아이디어가 4ms 더 빨랐음
//강의 답안
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
const n = input[0];
// 0~9까지 각 숫자(digit)의 출현 빈도를 담을 배열(array) 선언
const cnt = new Array(10).fill(0); // 초기 빈도 값은 0으로 초기화
for(let x of n) { // 한 자리씩 숫자(digit)를 확인하며 카운트 증가
cnt[Number(x)]++;
}
let answer = "";
for(let i = 9; i >= 0; i--) {
//출현 빈도 만큼 출력하기
for(let j = 0; j < cnt[i]; j++) {
answer += `${i}`;
}
}
console.log(answer);학습 일지 (+인증 사진)
1주차에서는 JavaScript 기본 문법과 자료 구조, 그리고 정렬에 대해 공부하였다.



자료 구조를 공부하기 전에는 업무 시에 알지 못하고 그냥 사용했던 반면, 이후에는 해당 자료 구조의 특징, 시간 복잡도 등을 고려해서 문제 해결에 적합한 자료 구조인지 생각하고 판단하여 사용할 수 있게 되었던 경험이 생각난다.
채용과정에서 자료구조 직접 구현하라는 경우를 아직 본 적이 없기 때문에, 챕터2에서 간단히 자료구조를 살펴보고 간 게 시간적으로 효율적일 수 있다고 생각이 들었다. 그래도 역시 기본기를 되돌아 본 다는 생각으로 천천히 하나씩 정리하면서 진행을 하다보니 여러 배운게 있는거 같다.
ES6 문법적으로 아래의 내용이 흥미로웠다.
1) spread operator (전개 구문)
// 예시
const arr = [...new Set(data)];
const arr = [0, ...input[i].split(' ').map(Number)];
2) destucturing assignment(구조분해 할당)
// 예시
const [n, m] = input[0].split(' ').map(Number);
console.log(n, m);그 외 Array.prototype API method 를 활용한 method chaining 등이 눈에 띄었고 익숙해 질 수 있었다.
정렬에서는 병합 정렬까지 무리 없이 진행하는 것이 가능했는데, 과거에는 퀵 정렬, 위상 정렬도 몇몇 강의에 챕터로 구성되어 있던거 같은데 이 강의에서는 없는 것으로 보아 요즘 유형에서는 벗어난게 아닌가 조심스레 추측을 해본다. 그래도 과거에 다른 언어로 해본 거라서 추후 포스팅을 작성해보는 시간을 가져야겠다. (얕은 복사와 깊은 복사 차이에 대해서도)
할 게 많지만 느리지만 천천히 한단계 올라가다보면 뒤돌아 봤을 때 성장한 모습을 또 볼 수 있지 않을가 싶다.
https://fastcampus.co.kr/dev_online_upjscodingtest
UPSKILL : Javascript 코딩테스트 131개 예제 & CS지식으로 끝내기 | 패스트캠퍼스
25시간 대비 과정 / '코테 레전드' 유튜버 강사님께 핵심만 배우고 빠르게 합격하세요.
fastcampus.co.kr
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'공부 > Javascript' 카테고리의 다른 글
| 패스트캠퍼스 JavaScript 코딩테스트 강의 한 달 후기 (3) | 2023.05.12 |
|---|---|
| 패스트캠퍼스 JavaScript 코딩테스트 강의 4주차 (0) | 2023.05.08 |
| 패스트캠퍼스 JavaScript 코딩테스트 강의 3주차 (0) | 2023.05.01 |
| 패스트캠퍼스 JavaScript 코딩테스트 강의 2주차 (0) | 2023.04.24 |
| 정규 표현식 문법 정리 (1) | 2023.01.24 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


